Comportamento
Entenda o que está mudando no seu ambiente — antes que cause impacto.
A maioria das ferramentas de monitoramento atua apenas de forma reativa: elas disparam alertas quando um determinado limite é ultrapassado. Mas e quando o sistema começa a apresentar sinais antes do problema acontecer?
Sobre o módulo Comportamento
O módulo Comportamento do Anomalus foi criado para preencher essa lacuna. Ele permite monitorar a evolução das métricas de forma contínua, comparando comportamentos históricos e detectando mudanças significativas mesmo quando os valores ainda estão dentro de limites aceitáveis.
Esse módulo é ideal para times de infraestrutura, operação, segurança e desenvolvimento que buscam prevenção real, eficiência operacional e controle proativo, substituindo o “achismo” por dados concretos sobre o que está se transformando em seu ambiente — e por quê.
O objetivo principal do módulo de Comportamento é permitir que as empresas tenham consciência das mudanças que estão ocorrendo no ambiente de TI — de forma detalhada, contínua e com base em inteligência artificial.
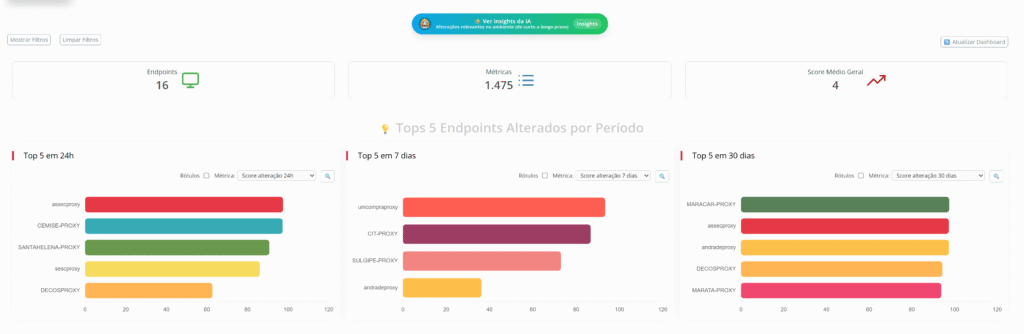
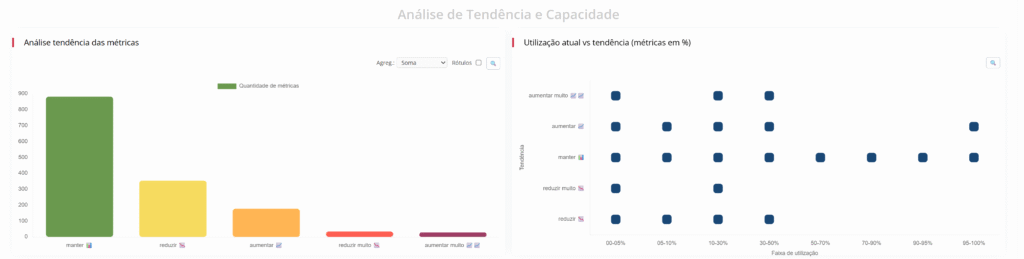
Ao invés de olhar apenas para o agora, o Anomalus olha para o padrão histórico de funcionamento de cada métrica, identifica tendências de evolução (positivas ou negativas) e prioriza visualmente o que está alterando de forma mais significativa.
Essa abordagem é essencial para:
Como funciona?
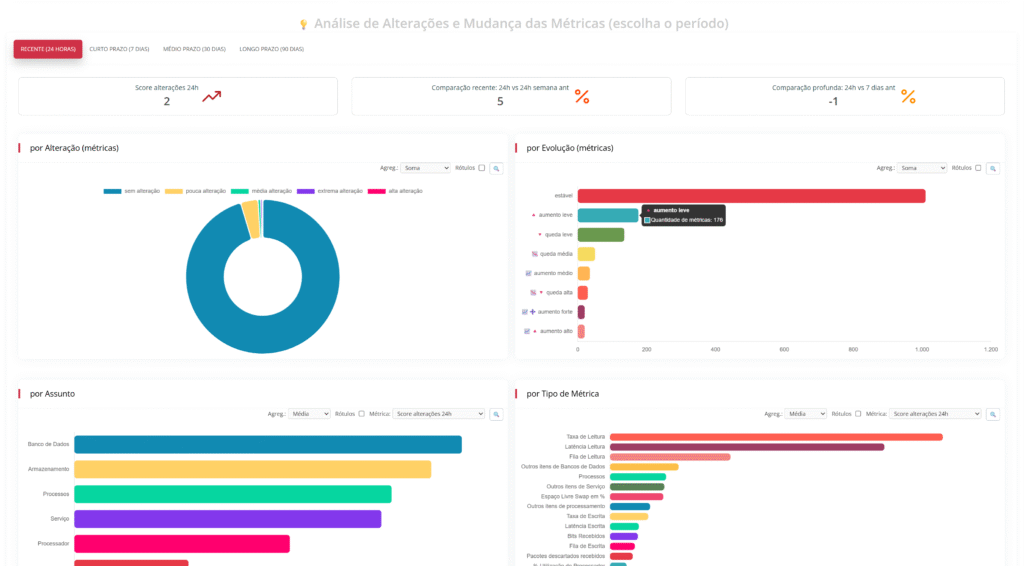
O Anomalus utiliza técnicas de análise comportamental com inteligência artificial para:
📊 O que você enxerga na prática:
Por que isso importa?
Enquanto os sistemas tradicionais só disparam alertas com base em limiares fixos (por exemplo, “uso de CPU > 90%”), o Anomalus identifica quando uma métrica está se comportando fora do padrão normal, mesmo que ainda não tenha atingido um nível crítico.
Isso permite:
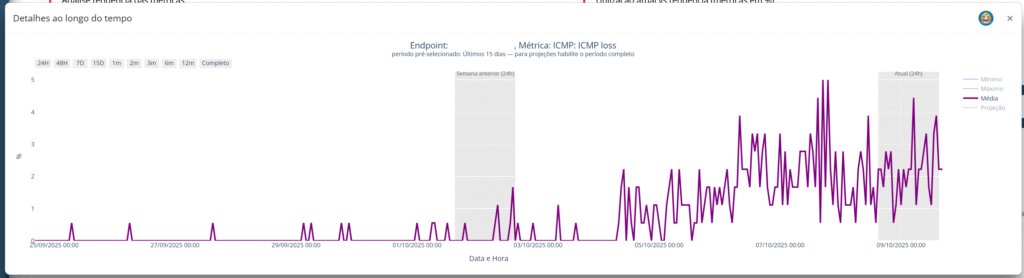
Exemplo real:
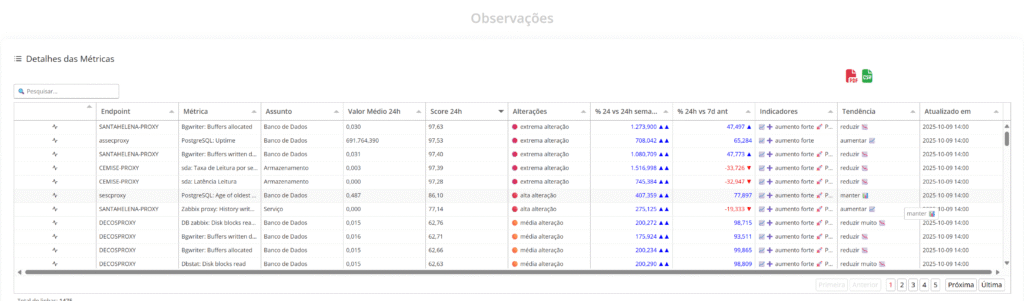
Imagine um ambiente onde o banco de dados está com aumento contínuo na latência de leitura. Ainda não gerou falha, mas os dados mostram aumento de buffers, pressão de I/O e queda progressiva no desempenho.
O Anomalus identifica isso com base na curva de comportamento, reconhece o risco antes do colapso, e informa qual recurso, métrica e endpoint estão no centro da mudança.