INTRODUÇÃO
CONHEÇA TUDO QUE O ANOMALUS PODE FAZER!
Monitoramento Proativo por IA
O Problema do Monitoramento Tradicional
Nós vivemos em um mundo de alertas que só disparam depois que o problema acontece. Somos notificados quando a CPU passa de 90% ou quando o disco está quase cheio.
Mas e quando o sistema começa a dar sinais de falha dias antes? E aquela degradação lenta de desempenho? E aquele comportamento estranho que ainda está “dentro dos limites aceitáveis”?
A maioria das ferramentas tradicionais é cega para isso. Elas nos forçam a viver “apagando incêndios”, agindo apenas de forma reativa.
A Mudança de Paradigma: De Reativo para Proativo
O Anomalus foi criado para preencher exatamente essa lacuna.
Nossa plataforma não se limita a perguntar “o limite foi ultrapassado?”. Nós perguntamos: “Este comportamento é normal?”
Utilizando inteligência artificial, o Anomalus aprende o padrão histórico de funcionamento de cada métrica em seu ambiente. Ele entende o que é normal para uma terça-feira às 10h da manhã e o que é normal para um sábado à noite.
O objetivo é simples: substituir o “achismo” por dados concretos, permitindo que sua equipe tenha consciência total do que está mudando no ambiente — e por quê.
Os Pilares do Anomalus
Nossa plataforma se sustenta em três pilares principais para entregar essa visão completa:
1. Detecção (O que está mudando?)
Primeiro, paramos de olhar apenas para o “agora” e olhamos para a evolução.
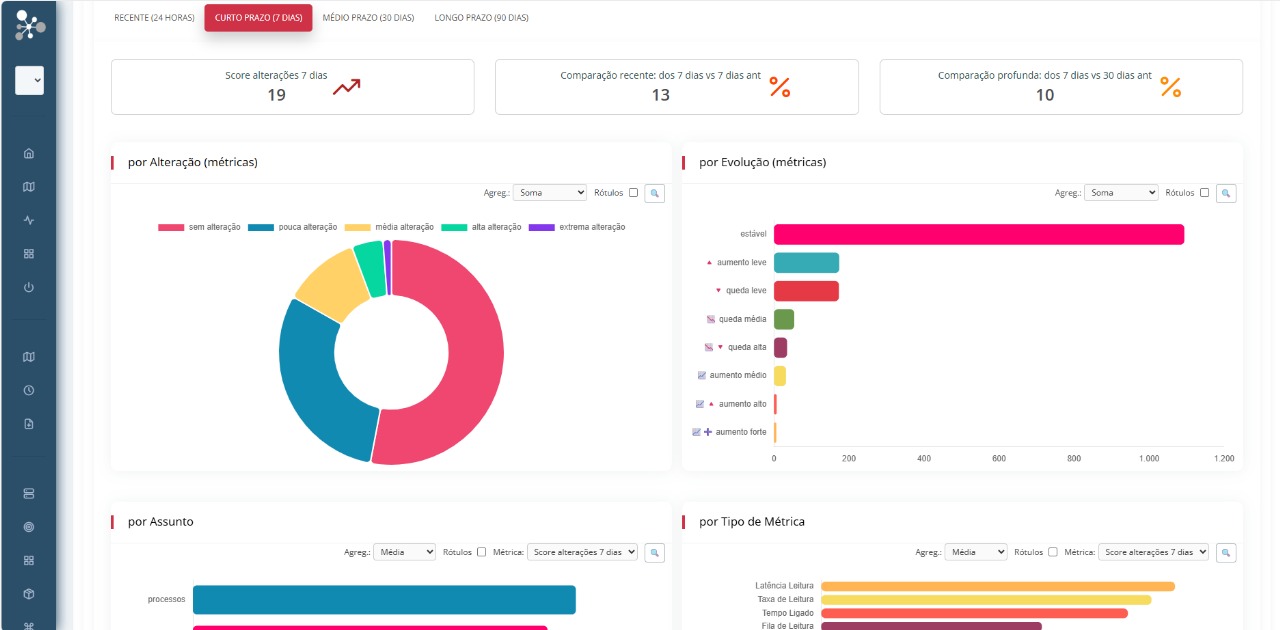
Módulo de Anomalias: Detectamos automaticamente “falhas ocultas”. Imagine que o uso de disco de um servidor sempre varia entre 65% e 75%. Se um dia ele sobe para 85% — mesmo que o limite de alerta seja 90% — o Anomalus identifica isso como um desvio do padrão e alerta sua equipe com contexto.
Módulo de Comportamento: Analisamos tendências de forma contínua. Mesmo que a latência de um banco de dados ainda esteja “aceitável”, estamos identificando se ela está subindo progressivamente dia após dia.
2. Previsibilidade (O que vai acontecer?)
Não basta ver o presente; temos que antecipar o futuro.
Exemplo Real: O sistema detecta um volume de armazenamento crescendo em ritmo acelerado. Mesmo com espaço livre, a projeção estatística indica que ele vai esgotar em 3 dias. O Anomalus gera um alerta preditivo, dando tempo para a equipe agir com calma, sem impacto no usuário.
Módulo de Previsibilidade e Foco: É aqui que transformamos manutenção corretiva em preditiva. Com base nas tendências e na análise histórica, o Anomalus prevê falhas.
3. Visão Unificada e Contexto (Onde devemos focar?)
De nada adianta ter dados se eles não estiverem organizados e acessíveis.
Mapa de Eventos: Criamos um painel visual dinâmico, ideal para equipes de NOC. Ele centraliza tudo o que está acontecendo (incidentes, anomalias) em tempo real, mostrando a saúde de todo o ambiente de forma imediata.
Agrupamento de Endpoints: Permitimos que você organize seus ativos por finalidade, localização ou cliente. Assim, você pode ver a saúde de um “setor” ou “filial” inteira de forma consolidada.
Disponibilidade Real: Medimos a disponibilidade não apenas com um “ping”, mas com base no que realmente importa para o seu negócio, seja o tempo de resposta de uma API ou o uso de CPU de um host crítico.
Integração Zabbix: Para quem usa Zabbix, atuamos como uma camada analítica que transforma dados brutos de alertas em dashboards estratégicos e visuais.

Resumo dos Benefícios
Ao adotar o Anomalus, sua organização ganha:
- Ação Proativa: Você age antes que a falha aconteça.
- Redução de Falhas: Você diminui incidentes causados por degradação lenta e picos silenciosos.
- Eficiência Operacional: Você reduz drasticamente o tempo de investigação e diagnóstico.
- Visão Preditiva: Você foca sua equipe no que vai ser um problema, e não apenas no que já é um problema.
O Anomalus é o fim da era dos “alertas” e o início da era da “inteligência operacional”.